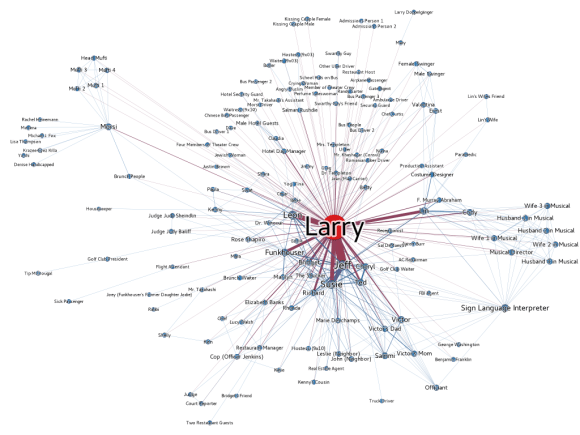
This is not a book review of Wanting: The Power of Mimetic Desire in Everyday Life. It is only a slice. Wanting should be subtitled ‘networks effects’. The book is based on network structure and connections but I can’t recall ‘network’ being used at all.
In mimesis, a centralized network is ‘Celebristan’. Our relationships with one-namers like Lebron or Cher is a centralized model. In mimesis, a dense, not centralized network is ‘Freshmanistan’, these are our relationships with roommates, neighbors, and colleagues.
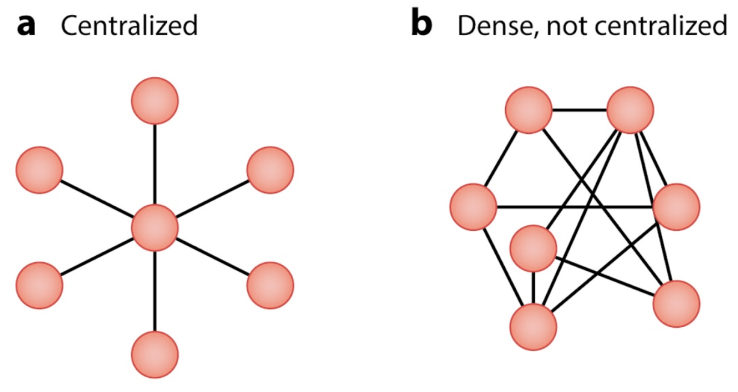
A network’s structure dictates information flow. Information is anything: ideas, vaccines, and so on. Lebron’s favorite salad dressing transfers widely, but only to us. He does not care about our top topping.
But, one-namers have dense networks with each other. Unacceptable: Privilege, Deceit & the Making of the College Admissions Scandal is an example of Burgis’s point. One-namers took the same trips, owned the same properties, bought the same toys. Though they were celebrity to us, their network was ‘Freshmanistan’.
The information in mimesis is status, rivalry, and desire.
Well, our best versions say, I don’t care about all that. This, mimesis OG Rene Girard said, is the romantic lie. Rivalry exists because we don’t really know what we want. “In the universe of desire,” Burgis writes, “there is no clear hierarchy.” It’s not that you want Ray-Ban sunglasses, it’s that someone else does.
This is my sticking point. I’m on board with the network structure and information flows. I’m okay with wants being fungible. But the conclusion feels wrong. Maybe.
There’s this dumb thing that happens to my wife and me. One of us suggests dinner, vacation, or weekend spot. The other mehs it. Time passes. A friend suggests that place to one of us. They go to the other and suggest it. ‘What the heck, I said that last month!’
Something is happening. Is it mimesis? I don’t know.
Status is an evolutionary advantage. Group membership helps us survive, and status games help the group because they are non-violent competitions. Draymond Green probably attacked teammate Jordan Poole because their status games were off. But the episode proves the point. Had Green’s punch landed, both individuals and the group would be hurt. Signs of status like cars, homes, jewelry, people, experiences prevent this conflict.
Is this mimesis? I don’t know.
Rather than rule on the mimetic ideas, we can triangulate them. In the spirit of looks like a duck, walks like a duck, talks like a duck. How does mimetic theory fit with…
Network theory? Great! Network theory is the underlying structure. All networks have information like covid viruses, neighborhood gossip, bumping electrons. Mimesis fits with our social networks.
JTBD? Surprisingly okay. In jobs theory people begin to ‘hire’ for solutions with “passive looking”. Maybe that stage is our social influences. If we are imitative then seeing one person with something might influence us.
Status games? Not bad. Mimetic rivalry creates the status hierarchy within a group.
Incentives? Less good. In the aggregate a bunch of people work to make as much money as possible. But does any one of them do that because they have a mimetic rivalry with any other? “The romantic lie” is great branding but incentives feel more right than mimesis.
The book confused me. It seems kinda right but not really right. But here we are, thinking about it, which may be mimetic itself.
…
A few network examples that didn’t make the post: The Zappos Holacracy was CEO Tony Hsieh’s attempt to recreate college, increase random interactions, and optimize “a return on collisions”.
The Theodore Roosevelt Covid outbreak as another example of network structure and information flows.